
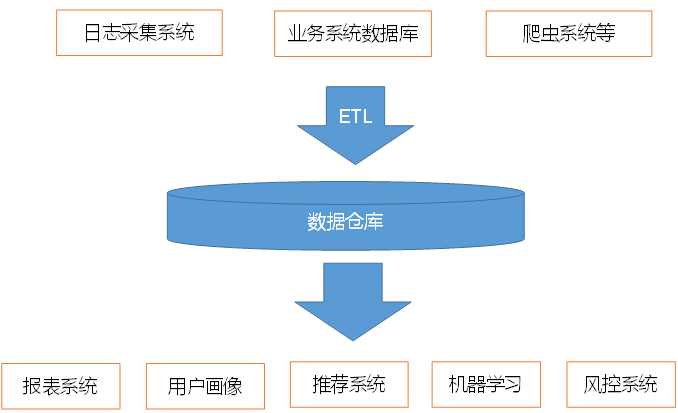
数据仓库的概念
讲到数据仓库(Data Warehouse)那就不得不提商业智能(Business Intelligence),每个企业的目标就是比竞争对手做出更好的商业决策,因此也就产生了BI的概念。通过BI将业务系统中大量的数据以易于理解的、当前的、准确的格式存储起来,以便于在其基础之上做出决策。然后,可以分析出当前和长期的趋势,立即注意到机会和问题,并不断收到关于决策有效性的反馈。而数据仓库则是BI解决方案中最重要的组成部分。
数据仓库是为企业所有决策制定过程,提供所有系统数据支持的战略集合。通过对数据仓库中数据的分析,可以帮助企业,改进业务流程、控制成本、提高产品质量等。
数据仓库的特点
- Subject-oriented 面向主题的
与业务系统(关系型数据库,nginx服务器等等)不同,数据仓库中的数据围绕企业的主题(数据库规范化)。
例如用户购买行为是一个主题,关系型数据库中存储的可能是订单金额,发货地址,物流信息等等。如果要考查用户的购买行为,可能就要统计一个用户从浏览到支付完成的时间,此时就要从nginx访问日志中提取相关数据,并将所有这些数据归并分类整合。收集所需的分析对象称为面向主题,主题导向对决策非常有用。 - Integrated 综合的
在数据仓库中的数据是集成的。由于它来自多个业务系统,所以必须消除所有的不一致性。一致性包括命名约定、变量度量、编码结构、数据的物理属性等等。 - Time-variant 时变性的
业务系统支持日常操作因此反映的当前值,但数据仓库数据表示长期(最多10年)的数据,这意味着它存储历史数据。它主要用于数据挖掘和预测,如果用户想知道特定客户的购买模式,那么就需要查看当前和过去购买的数据。 - Nonvolatile 非易失性的
数据仓库中的数据是只读的,这意味着它不能更新、创建(insert操作)或删除。 - Summarized 概述性的
在数据仓库中,数据在不同的级别进行汇总。例如用户开始查看一个产品在全国的总销售额。然后再去查看某个省份的某个城市的销售额。最后,他们可以在特定的城市下检查各个商店的销售额。因此,通常情况下,分析是从更高的层次开始,然后向下移动到更低的细节层次。
数仓相关的概念
数据集市(Data Market)
数据集市是数据仓库的一种简单的形式,它只专注于一个主题或者是一个职能范围,如销售、财务或营销,因此,他们的数据来源有限。数据集市是部门级的,只能为某个局部范围内的管理人员服务。
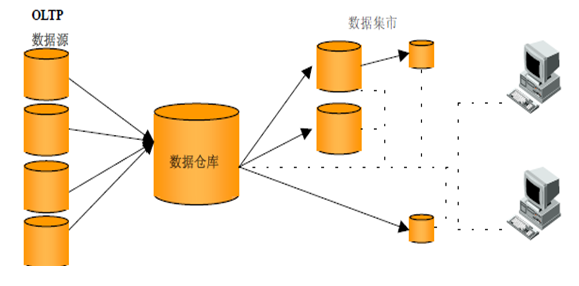
tips: 数据的来源可以是内部业务系统、中央数据仓库或外部数据。
OLTP versus OLAP
OLTP:On-Line Transaction Processing在线事务处理,针对具体的业务在数据库中的在线操作,具有数据量较少的特点,通常对少量的数据记录进行查询、修改。典型的就是我们的关系型数据库如MySQL、Oracle。
OLAP:On-Line Analytical Processing在线分析处理,针对某些主题(综合数据)的历史数据进行分析,支持管理决策。例如数据仓库hive。
| 比较项 | 操作型(OLTP) | 分析性(OLAP) |
|---|---|---|
| 关注 | 细节 | 综合或提炼 |
| 模型 | 实体–关系(E-R) | 星型或雪花 |
| 操作 | 可更新 | 只读,只追加 |
| 操作粒度 | 操作一个单元 | 操作一个集合 |
| 场景 | 面向事务 | 面向分析 |
| 数据量 | 小 | 大 |
Predictive Analytics预测分析
预测分析是使用复杂的数学模型来发现和量化数据中的隐藏模式,这些模型可以用来预测未来的结果。预测分析不同于OLAP, OLAP侧重于历史数据分析,具有反应性,而预测分析侧重于未来。这些系统也用于客户关系管理(CRM)。
数据仓库的好处
- 将来自多个数据源的数据集成到单个数据库和数据模型中,因此可以使用单个查询引擎在ODS(原始数据层)中表示数据。
- 集成来自多个源系统的数据,支持跨企业的中心视图。这种好处总是很有价值的,特别是当组织通过合并而成长的时候。
- 为所有感兴趣的数据提供一个通用的数据模型,而不管数据的来源。通过提供一致的代码和描述、标记甚至修复错误的数据来提高数据质量。始终如一地展示企业的信息。
- 重构数据,组织和消除重复数据的歧义,使其对业务用户有意义,并使得决策支持的查询更容易编写,还能够提供出色的查询性能,即使对于复杂的分析查询,也不会影响业务系统。
- 维护数据历史记录,即使源事务系统不这样做。
数仓分层的概念
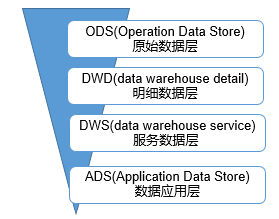 ODS层:原始数据层,存放原始数据,直接加载原始日志、数据,数据保持原貌不做处理。
ODS层:原始数据层,存放原始数据,直接加载原始日志、数据,数据保持原貌不做处理。
DWD层:结构和粒度与原始表保持一致,对ODS层数据进行清洗(去除空值,脏数据,超过极限范围的数据)。
DWS层:以DWD为基础,进行轻度汇总。
ADS层:为各种统计报表提供数据。
tips: 这只是数仓分层的一种,可能每个企业中有所不同,但都大同小异。
数仓为什么要分层
- 把复杂问题简单化
将一个复杂的任务分解成多个步骤来完成,每一层只处理单一的步骤,比较简单、并且方便定位问题。 - 减少重复开发
规范数据分层,通过的中间层数据,能够减少极大的重复计算,增加一次计算结果的复用性。 - 隔离原始数据
不论是数据的异常还是数据的敏感性,使真实数据与统计数据解耦开。