
事实(facts)和维度(dimensions)
fact就是值或者说是度量(measurement),它代表着管理实体和系统的一个事实。 fact一般是原生级别(raw level)的,例如:在移动电话系统中,基站收发站(BTS, base transceiver station)接收到了1000通信信道分配(traffic channel allocation)请求,分配了820个并拒绝了剩余的请求,那么就有如下三个关于管理系统的事实:
- tch_req_total = 1000
- tch_req_success = 820
- tch_req_fail = 180
原生级别的facts通过不同的维度(dimension)聚合至更高层次以获取更多的服务或者是商业相关的信息,它们被称之为aggregates、summaries、aggregated facts.例如:某个城市中有三个BTS,那么上面的这些facts在城市级别之下网络维度之上可以被聚合如下:
- tch_req_success_city = tch_req_success_bts1 + tch_req_success_bts2 + tch_req_success_bts3
- avg_tch_req_success_city = (tch_req_success_bts1 + tch_req_success_bts2 + tch_req_success_bts3) / 3
tips:
维度dimension,就是数据的观察角度,即从哪个角度去分析问题,看待问题。维度一般是一个离散的值,比如时间维度上每一个独立的日期或地域,因此统计时,可以把维度相同记录的聚合在一起,应用聚合函数做累加、均值、最大值、最小值等聚合计算。
度量measurement,就是在维度的基础上被聚合的那个值(上例中的tch_req_success_bts1、tch_req_success_bts2…)。一般是一个连续的值。
数仓建模
将数据存储到数据仓库有以下两种最重要的方法:
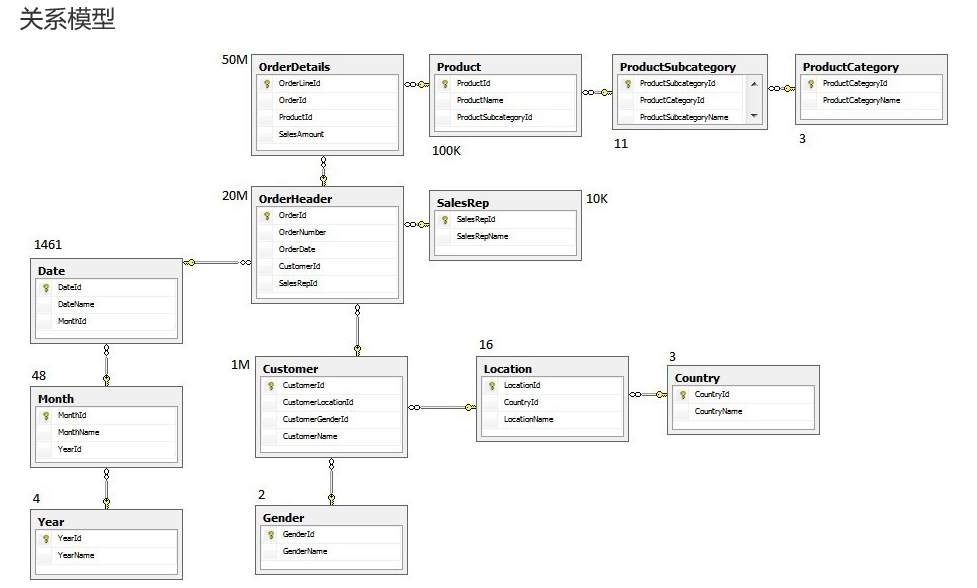
规范化方法(normalized approach)
规范化方法,也称为3NF模型(第三范式),是指Bill Inmon提出的数据仓库应该使用E-R模型/规范化模型建模的方法。
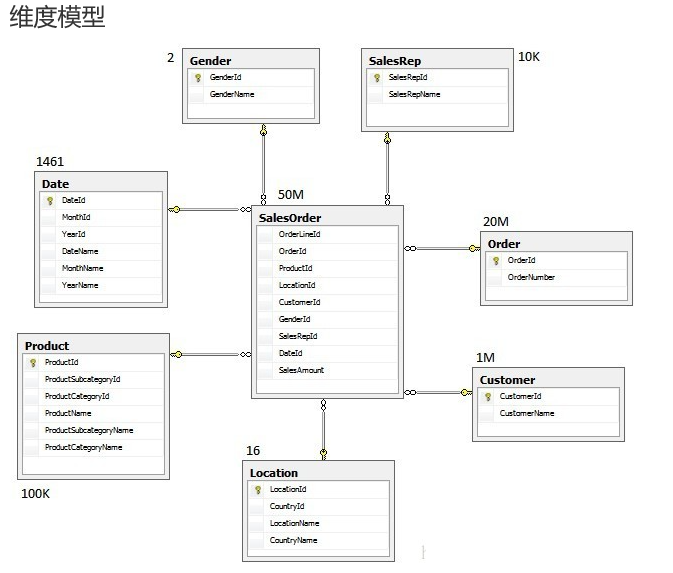
维度方法(dimensional approach)
维度方法指的是Ralph Kimball的方法,其中声明数据仓库应该使用维度模型/星型模式建模。
范式理论
范式概念
关系型数据库设计时,遵照一定的规范要求,目的在于降低数据的冗余性,目前业界范式有:第一范式(1NF)、第二范式(2NF)、第三范式(3NF)、巴斯-科德范式(BCNF)、第四范式(4NF)、第五范式(5NF)。 范式可以理解为一张数据表的表结构,符合的设计标准的级别。 使用范式的根本目的是:
- 减少数据冗余,尽量让每个数据只出现一次。
- 保证数据一致性
缺点是获取数据时,需要通过Join拼接出最后的数据。
函数依赖
-
学生成绩表如下:
学号 姓名 系名 系主任 课名 分数 1101 李小明 经济系 王强 高等数学 95 1101 李小明 经济系 王强 大学英语 87 1101 李小明 经济系 王强 普通化学 76 1102 张莉莉 经济系 王强 高等数学 72 1102 张莉莉 经济系 王强 大学英语 98 1102 张莉莉 经济系 王强 计算机基础 88 1103 高芳芳 法律系 刘玲 高等数学 82 1103 高芳芳 法律系 刘玲 法学基础 82 - 完全函数依赖
设X,Y是关系R的两个属性集合,X’是X的真子集,存在X→Y,但对每一个X’都有X’!→Y,则称Y完全函数依赖于X。
人类语言:比如通过(学号,课程) 推出分数,但是 单独用学号推断不出来分数,那么就可以说:分数 完全依赖于(学号,课程)。
即:通过AB能得出C,但是AB单独得不出C,那么说C完全依赖于AB。 - 部分函数依赖
假如 Y函数依赖于 X,但同时 Y 并不完全函数依赖于 X,那么我们就称 Y 部分函数依赖于 X。
人类语言:比如通过(学号,课程) 推出姓名,因为其实直接可以通过学号推出姓名,所以:姓名 部分依赖于 (学号,课程)
即:通过AB能得出C,通过A也能得出C,或者通过B也能得出C,那么说C部分依赖于AB。 - 传递函数依赖
设X,Y,Z是关系R中互不相同的属性集合,存在X→Y(Y !→X),Y→Z,则称Z传递函数依赖于X。
人类语言:比如学号 推出 系名 , 系名 推出 系主任, 但是,系主任推不出学号,系主任主要依赖于系名。这种情况可以说:系主任 传递依赖于 学号。
通过A得到B,通过B得到C,但是C得不到A,那么说C传递依赖于A。
三范式区分
-
第一范式1NF核心原则就是:属性不可切割
不符合一范式的表格设计:ID 商品 商家ID 用户ID 001 5台电脑 XXX旗舰店 00001 很明显上图所示的表格设计是不符合第一范式的,商品列中的数据不是原子数据项,是可以进行分割的,因此对表格进行修改,让表格符合第一范式的要求,修改结果如下图所示:
符合一范式的表格设计:ID 商品 数量 商家ID 用户ID 001 电脑 5 XXX旗舰店 00001 实际上,1NF是所有关系型数据库的最基本要求,你在关系型数据库管理系统(RDBMS),例如SQL Server,Oracle,MySQL中创建数据表的时候,如果数据表的设计不符合这个最基本的要求,那么操作一定是不能成功的。也就是说,只要在RDBMS中已经存在的数据表,一定是符合1NF的。
-
第二范式2NF核心原则:不能存在“部分函数依赖”
学号 姓名 系名 系主任 课名 分数 1101 李小明 经济系 王强 高等数学 95 1101 李小明 经济系 王强 大学英语 87 1101 李小明 经济系 王强 普通化学 76 1102 张莉莉 经济系 王强 高等数学 72 1102 张莉莉 经济系 王强 大学英语 98 1102 张莉莉 经济系 王强 计算机基础 88 1103 高芳芳 法律系 刘玲 高等数学 82 1103 高芳芳 法律系 刘玲 法学基础 82 以上表格明显存在部分依赖。比如,这张表的主键是 (学号,课名),分数确实完全依赖于 (学号,课名),但是姓名并不完全依赖于(学号,课名)
学号 课名 分数 1101 高等数学 95 1101 大学英语 87 1101 普通化学 76 1102 高等数学 72 1102 大学英语 98 1102 计算机基础 88 1103 高等数学 82 1103 法学基础 82 学号 姓名 系名 系主任 1101 李小明 经济系 王强 1102 张莉莉 经济系 王强 1103 高芳芳 法律系 刘玲 以上符合第二范式,去掉部分函数依赖依赖
-
第三范式 3NF核心原则:不能存在传递函数依赖 在下面这张表中,存在传递函数依赖:学号->系名->系主任,但是系主任推不出学号。
学号 姓名 系名 系主任 1101 李小明 经济系 王强 1102 张莉莉 经济系 王强 1103 高芳芳 法律系 刘玲 上面表需要再次拆解:
学号 姓名 系名 1101 李小明 经济系 1102 张莉莉 经济系 1103 高芳芳 法律系 系名 系主任 经济系 王强 法律系 刘玲
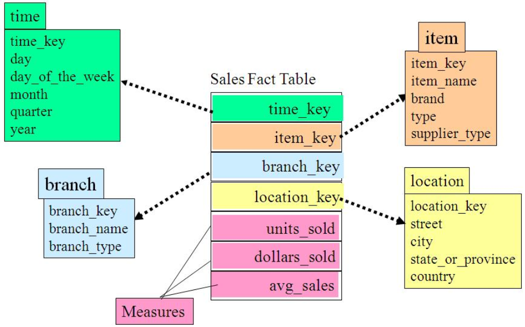
雪花模型、星型模型和星座模型
星型模型
雪花模型
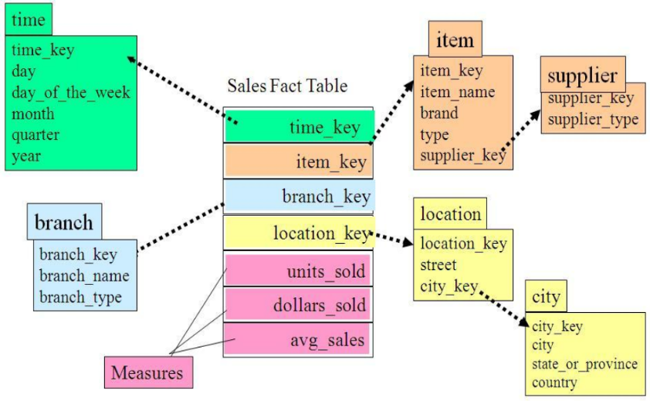
星座模型
基本上是很多数据仓库的常态,因为很多数据仓库都是多个事实表的。所以星座不星座只反映是否有多个事实表,他们之间是否共享一些维度表。 所以星座模型并不和前两个模型冲突。
模型的选择
首先就是星座不星座这个只跟数据和需求有关系,跟设计没关系,不用选择。
星型还是雪花,取决于性能优先,还是灵活更优先。
目前实际企业开发中,不会绝对选择一种,根据情况灵活组合,甚至并存(一层维度和多层维度都保存)。但是整体来看,更倾向于维度更少的星型模型。尤其是Hadoop体系,减少Join就是减少Shuffle,性能差距很大。(关系型数据可以依靠强大的主键索引)
表的分类
事实表(fact table)
事实表,一般是指一个现实存在的业务对象,比如用户,商品,商家,销售员等等。
用户表:
| 用户ID | 姓名 | 生日 | 性别 | 邮箱 | 用户等级 | 创建时间 |
|---|---|---|---|---|---|---|
| 0001 | 张三 | 2011-11-11 | 男 | zs@163.com | 2 | 2018-11-11 |
| 0002 | 李四 | 2011-11-11 | 女 | ls@163.com | 3 | 2018-11-11 |
| 0003 | 王五 | 2011-11-11 | 男 | ww@163.com | 1 | 2018-11-11 |
| … | … | … | … | … | … | … |
维度表(dimension table、lookup table)
维度表,一般是指对应一些业务状态,编号的解释表。也可以称之为码表。比如地区表,订单状态,支付方式,审批状态,商品分类等等。
订单状态表:
| 订单状态编号 | 订单状态名称 |
|---|---|
| 1 | 未支付 |
| 2 | 支付 |
| 3 | 发货中 |
| 4 | 已发货 |
| 5 | 已完成 |
商品分类表:
| 商品分类编号 | 分类名称 |
|---|---|
| 1 | 服装 |
| 2 | 保健 |
| 3 | 电器 |
| 4 | 图书 |
事务型事实表
事务型事实表,一般指随着业务发生不断产生的数据。特点是一旦发生不会再变化。一般比如交易流水,操作日志,出库入库记录等等。
交易流水表:
| 编号 | 对外业务编号 | 订单编号 | 用户编号 | 交易流水编号 | 支付金额 | 交易内容 | 支付类型 | 支付时间 |
|---|---|---|---|---|---|---|---|---|
| 0001 | 7577697945 | 0001 | 000111 | QEyF-63000323 | 223.00 | aaaaa | alipay | 2019-02-10 00:01:29 |
| 0002 | 0170099522 | 0002 | 000222 | qdwV-25111279 | 589.00 | bbbbb | wechatpay | 2019-02-10 00:05:02 |
| 0003 | 1840931679 | 0003 | 000666 | hSUS-65716585 | 485.00 | ccccc | unionpay | 2019-02-10 00:50:02 |
周期型事实表
周期型事实表,一般指随着业务发生不断产生的数据。与事务型不同的是,数据会随着业务周期性的推进而变化。比如订单,其中订单状态会周期性变化。再比如请假、贷款申请,随着批复状态在周期性变化。
订单表:
| 订单编号 | 订单金额 | 订单状态 | 用户id | 支付方式 | 支付流水号 | 创建时间 | 操作时间 |
|---|---|---|---|---|---|---|---|
| 0001 | 223.00 | 0002 | 000111 | alipay | QEyF-63000323 | 2019-02-10 00:01:29 | 2019-02-10 00:01:29 |
| 0002 | 589.00 | 0002 | 000222 | wechatpay | qdwV-25111279 | 2019-02-10 00:05:02 | 2019-02-10 00:05:02 |
| 0003 | 485.00 | 0001 | 000666 | unionpay | hSUS-65716585 | 2019-02-10 00:50:02 | 2019-02-10 00:50:02 |
同步策略
数据同步策略的类型包括:全量表、增量表、新增及变化表、拉链表
- 全量表:存储完整的数据。
- 增量表:存储新增加的数据。
- 新增及变化表:存储新增加的数据和变化的数据。
- 拉链表:对新增及变化表做定期合并。
事实表同步策略
事实表:比如用户,商品,商家,销售员等
事实表数据量比较小:通常可以做每日全量,就是每天存一份完整数据。即每日全量。
维度表同步策略
维度表:比如订单状态,审批状态,商品分类
维度表数据量比较小:通常可以做每日全量,就是每天存一份完整数据。即每日全量。
说明:
- 针对可能会有变化的状态数据可以存储每日全量。
- 没变化的客观世界的维度(比如性别,地区,民族,政治成分,鞋子尺码)可以只存一份固定值。
事务型事实表同步策略
事务型事实表:比如,交易流水,操作日志,出库入库记录等。
因为数据不会变化,而且数据量巨大,所以每天只同步新增数据即可,所以可以做成每日增量表,即每日创建一个分区存储。
周期型事实表同步策略
周期型事实表:比如,订单、请假、贷款申请等
这类表从数据量的角度,存每日全量的话,数据量太大,冗余也太大。如果用每日增量的话无法反应数据变化。
,包括了当日的新增和修改。一般来说这个表,足够计算大部分当日数据的。但是这种依然无法解决能够得到某一个历史时间点(时间切片)的切片数据。
所以要用利用每日新增和变化表,制作一张拉链表,以方便的取到某个时间切片的快照数据。所以我们需要得到每日新增及变化量。 拉链表:
| name | start time | end time |
|---|---|---|
| 张三 | 1990/1/1 | 2018/12/31 |
| 张小山 | 2019/1/1 | 2019/4/30 |
| 张大山 | 2019/5/1 | 9999-99-99 |
select * from user where start <='2019-1-2' and end >='2019-1-2'